Ring Attention - scaling attention across multiple devices
Ring Attention is a technique to scale the attention mechanism across multiple devices (GPUs). This allows for scaling to large context sizes by adding more devices. Let’s see how it works.
But first, a quick refresher on the attention mechanism, which you can skip if you’re already familiar with it. Attention (specifically scaled dot-product attention) is defined as:
$$ O = Attention(Q,K,V) = softmax({{QK^T}\over{\sqrt{d_{head}}}})V $$
- There is an input sequence $X$ (not shown above), which has dimensions
(n_context, d_model). (So $X$ isn_contextrows each of which has dimensiond_model) - $Q, K, V$ are produced from Linear layers which reduce/project the dimension down to
d_head. So they are all of dimension(n_context, d_head) - $QK^T$ produces a matrix of size
(n_context, n_context)and represents the pre-softmax logits. These are normalized by the square root ofd_head. (I’ll ignore this scaling/normalization factor from now on) - Softmax is applied row-wise to $QK^T$ to transform each row into a discrete probability distribution. This is applied to $V$ to produce a weighted output of each row of $V$ into the rows of the output $O$, which also has dimension
(n_context, d_head)
I covered this in my previous article on FlashAttention, but as a reminder here’s a visual overview of the operations:
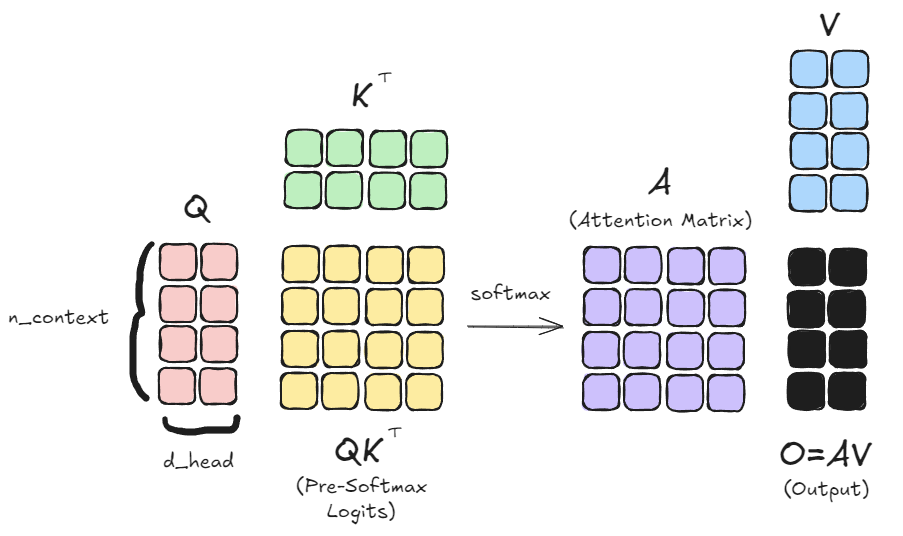
The key points to understand are:
- Each query row in $Q$ corresponds to one output row in $O$.
- Each query row in $Q$ must be interacted with potentially all rows of $K, V$ to produce one output row in $O$. (It’s all rows in the general case of self-attention, and all previous rows in the case of masked self-attention)
- It’s this interaction which represents the attention mechanism, and allows the tokens to “communicate” with one another.
From this the complexity can be estimated:
- Because each token must interact with potentially every other token, the computation cost is $O(n^2)$ in the sequence length/context size.1
- A naive implementation of attention would also have a memory complexity of $O(n^2)$ in the sequence length if it materialized the entire attention matrix.
FlashAttention reduced the memory complexity to $O(n)$ by processing one or more $K, V$ rows at a time (for each query row in $Q$) and accumulating the output into $O$, thus avoiding materialization of the entire attention matrix. However this is the best we can do since the size of the $Q, K, V$ matrices themselves are directly proportional to the sequence length.
So we cannot reduce the compute and memory cost any further, but can we distribute the cost across multiple devices (GPUs) to scale the attention mechanism horizontally with large context sizes? Ring Attention proposes a scheme for just this.
Ring Attention Details
From a high level, we need to:
- Distribute the $Q, K, V$ matrices across multiple devices.
- Somehow “share” the $K, V$ blocks across devices so that all query rows in $Q$ are able to interact with them to produce the output $O$.
Ring Attention accomplishes this in the following steps:
- Split (or shard) the $Q, K, V$ matrices across $d$ devices, so that each device gets a “block” of rows from each. For simplicity, we assume that the sequence length $n$ is an integer multiple of $d$, so each device will get a block of $n/d$ rows from each of $Q, K, V$, so our block size is $n/d$
- Arrange the devices in a logical ring.
- In the first step, each device will process its $Q$ block against its own $K, V$ blocks to produce a partial output in its $O$ block. Then it will send its $K, V$ blocks to the next device in the ring.
- On the next step, each device will receive the $K, V$ blocks sent from the previous device, process these new blocks against its $Q$ block, and update the partial output in $O$. It will then send these $K, V$ blocks onto the next device.
- After $d$ steps, the output block $O$ will contain the final result for the rows on that device.
In steps (3) and (4), the output needs to be iteratively updated (accumulated into), since each query block (set of rows) is never able to see all $K, V$ rows at the same time. This usually means an algorithm like FlashAttention is used for this inner loop. (The outer loop being the $d$ steps)
Here’s what this looks like with $d=4$ devices and $n = 4$ sequence length:
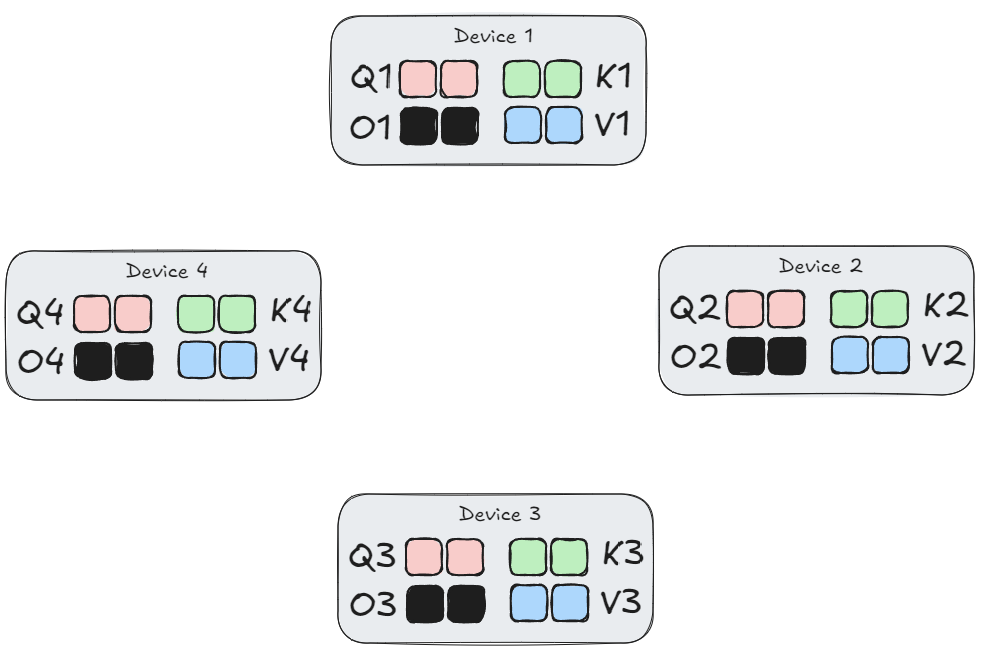
On the first step, each device interacts its local query block $Q_i$ with its local $K_j, V_j$ blocks using FlashAttention to compute and accumulate the partial result into local output block $O_i$. (We’ll use $i$ to denote the device index and $j$ to denote the index of the $K, V$ blocks being processed on that device)
On the next step, each device sends its local $K_j, V_j$ blocks to the next device, so that device $i$ receives the $i-1$ blocks from its previous neighbor. These blocks are then interacted with the local query block to accumulate the result into the local output block. So for the second step we do this:
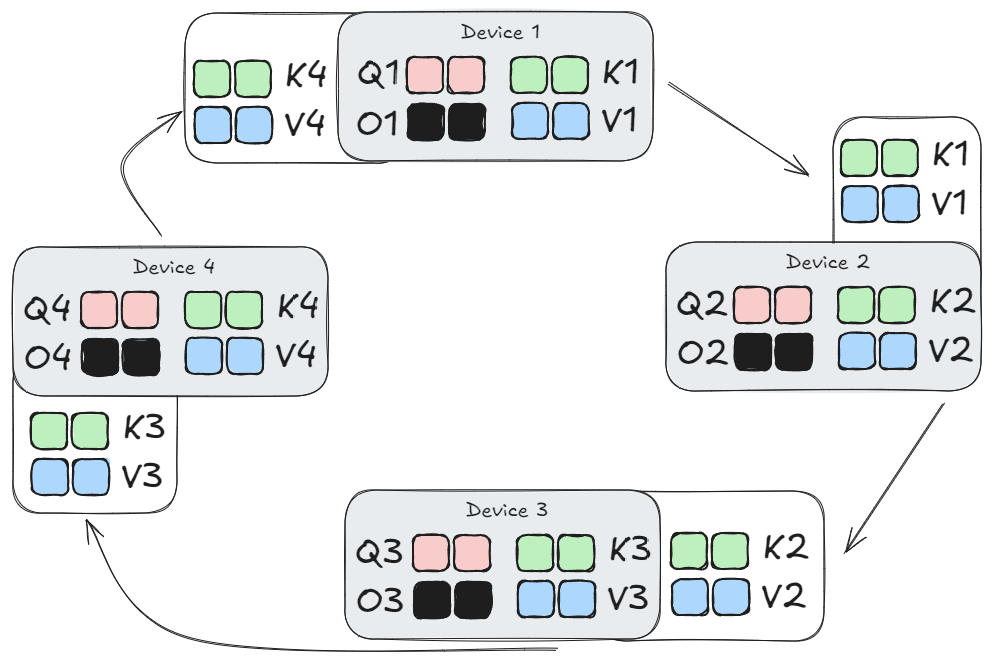
- Device 1 sends $K_1, V_1$ to Device 2, and receives $K_4, V_4$ from Device 4.
- Device 1 then processes/interacts its local $Q_1$ block with the received $K_4, V_4$ blocks to update the local result in $O_1$
- The same steps (1) and (2) happen in parallel across all devices.
- Note that this requires extra memory space on each device to buffer the received $K_j, V_j$ blocks.
On the third step, previously received $K_j, V_j$ blocks are sent to the next device. In our example, this would be:
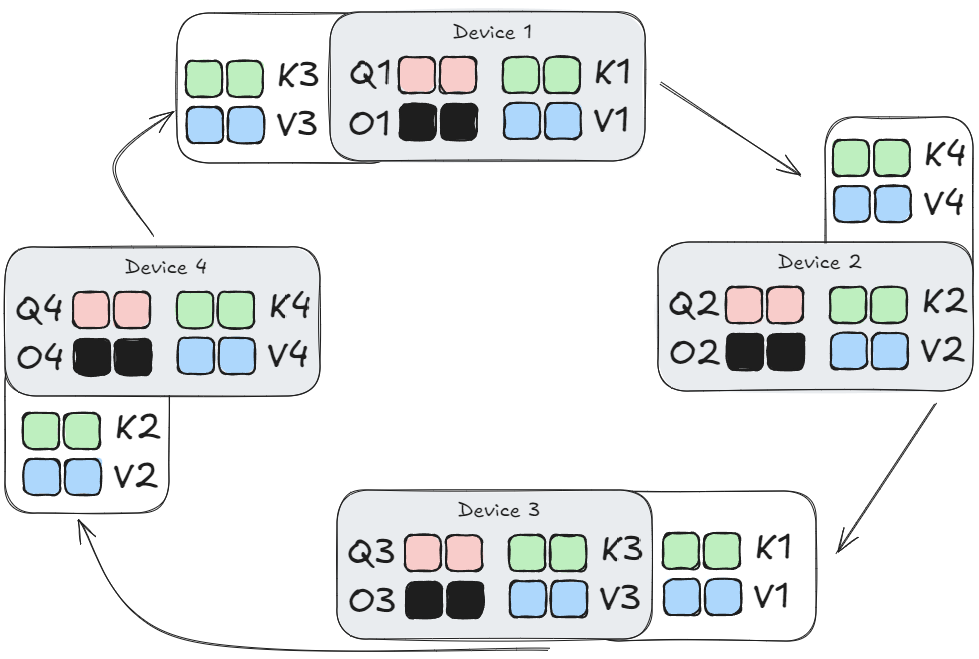
The output $O$ remains sharded across multiple devices, but that’s OK, because:
- The non-attention layers in transformers operate on a per-token level
- When we get to the next attention layer, the input needs to be sharded anyways, since those layers will also implement Ring Attention
There is obviously a network cost to passing the $K_j, V_j$ blocks between devices like this. But as discussed in the Ring Attention paper in section 3, this can be mitigated by concurrently doing the computation and communication. From the paper:
Concretely, for any host-$i$, during the computation of attention between its query block and a key-value block, it concurrently sends key-value blocks to the next host-$(i + 1)$ while receiving key-value blocks from the preceding host-$(i − 1)$. If the computation time exceeds the time required for transferring key-value blocks, this results in no additional communication cost.
This means selecting a block size such that the network latency of sending the $K, V$ blocks from one GPU to the next is similar to the time it takes to compute attention between those blocks and each device’s local query block. This depends on the inter-device network bandwidth, each device’s compute FLOPS, the overall context length, and the number of devices. (See here for further explanation)
Simulation of Ring Attention
Here is some sample Python code which simulates Ring Attention: (Full simulation code here)
# Ring Attention Simulation
class Device(threading.Thread):
def __init__(self, device_id, q, k, v, barrier, n_workers):
super().__init__()
# ... rest omitted for brevity ...
def run(self):
for step in range(n_workers):
# Special case: First step: Process device's own k, v blocks
k, v = self.k, self.v # k, v can be considered the buffer for received k, v blocks from the previous device
if step != 0:
k, v = self.recv()
# Barrier to ensure all devices/workers have read/received K, V blocks from their buffers
self.barrier.wait()
if step != n_workers - 1: # No need to send on last step
send(self.next_id, self.device_id, (k, v))
# Barrier to ensure all devices/workers have sent K, V blocks to the next device's buffers
self.barrier.wait()
# Local flash attention to update output block
self.o, self.mins, self.denoms = flashattention(self.q, k, v, self.o, self.mins, self.denoms)
# ... rest omitted for brevity ...
In this simulation, Python threads are used to represent the separate devices and “communication” between the devices is accomplished through serialization/deserialization of data (to simulate network cost) and barriers to synchronize communication between devices. FlashAttention is used to implement the “local loop” where we iterate over the rows of the received $K_j, V_j$ blocks to interact them with the local $Q_i$ block to accumulate output into the local $O_i$ block.
By using Ring Attention, each device never has to store the entire context. Instead, the context is effectively partitioned across all devices, with each device only handling a “block” of the context. This reduces the memory footprint, especially when you have large context sizes with KV cache.
-
For plain old vanilla attention, the compute cost is $O(n^2)$ in the sequence length, but techniques like Sliding Window Attention can reduce to this to $O(nw)$ where $w$ is the window size. This is a trade-off between compute cost and model performance. ↩︎